python爬虫学习(一)
1.前言
本篇开始想要从基础的爬虫案例开始,逐步完成爬虫相关技术的学习,在本篇中,我会用东方财富 、51游戏、中国人事考试网等案例进行,从易到难。
2.爬虫功能分类
在进行案例之前先说明一下爬虫的功能分类,一共有如下几种
- 通用爬虫:直接对页面的所有数据进行爬取
- 聚焦爬虫:对页面中的数据有选择性的爬取
- 功能爬虫:通过浏览器或者app实现自动化爬取
- 增量式爬虫:对新更新的数据进行补充爬取,以前爬取的数据不再新爬取
- 分布式爬虫:搭建分布式集群对网络资源进行联合且分布的爬取
当然本篇的案例只是很基础的案例,甚至代码都不会多
3.1 东方财富网
1 | import requests |
通过运行上方代码即可得到,下述内容的文件
在右上角四个浏览器中选择一个进入即可看到爬取成果
3.2 51游戏网
网址:https://www.51.com/
上一个案例中,只是简单的对url的首页进行通用爬取,但事实上你进入一个网站肯定不会只因为其主页,比如这个游戏网,你若想搜集带有“王者”这个关键词的游戏仅靠先前给出代码无法实现该需求
此时可以先进入网页去搜索看看相关的网址会是什么样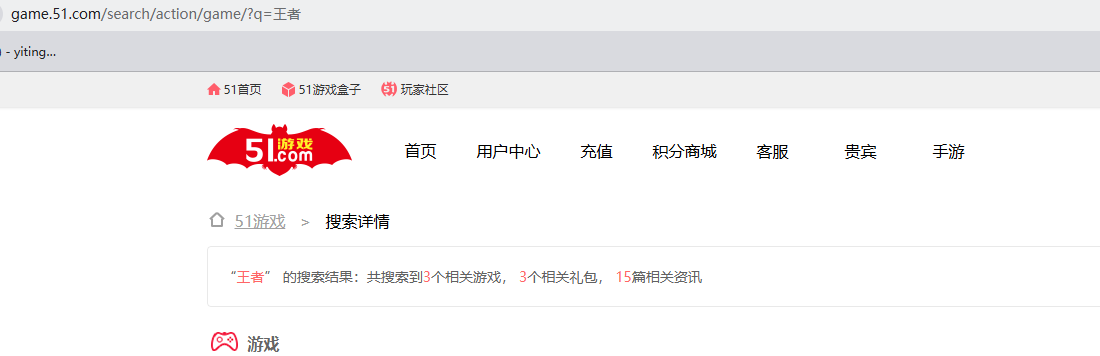
通过类似输入多个关键词,会发现url前面https://game.51.com/search/action/game/都没有改变,只有后面的"王者"这个关键词变化了,所以对应的代码也会对应变化
1 | import requests |
3.3 中国人事考试网
- 网址 http://www.cpta.com.cn/
如果你根据先前的代码去进行爬取,并不会报错,但是当你将爬取到的网址打开以后并不会得到对应网址,而是如下图的报错。
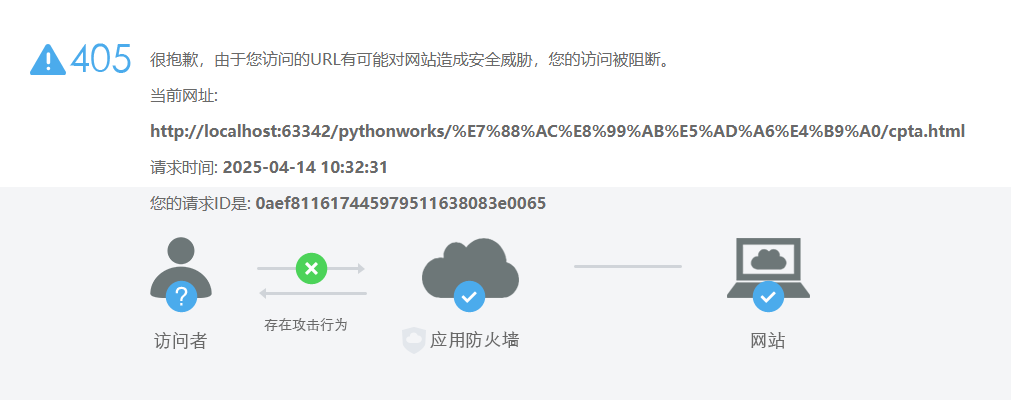
于是据此,提出一个说法,对于此类问题都是由于爬虫模拟浏览器的程度不够,网站认为我的这个id不正常,不属于正常用户访问浏览器的id所以无法进行爬取,所以,我们需要在代码中加入header,也就是请求头,你可以通过在浏览器中按F12,进入开发者模式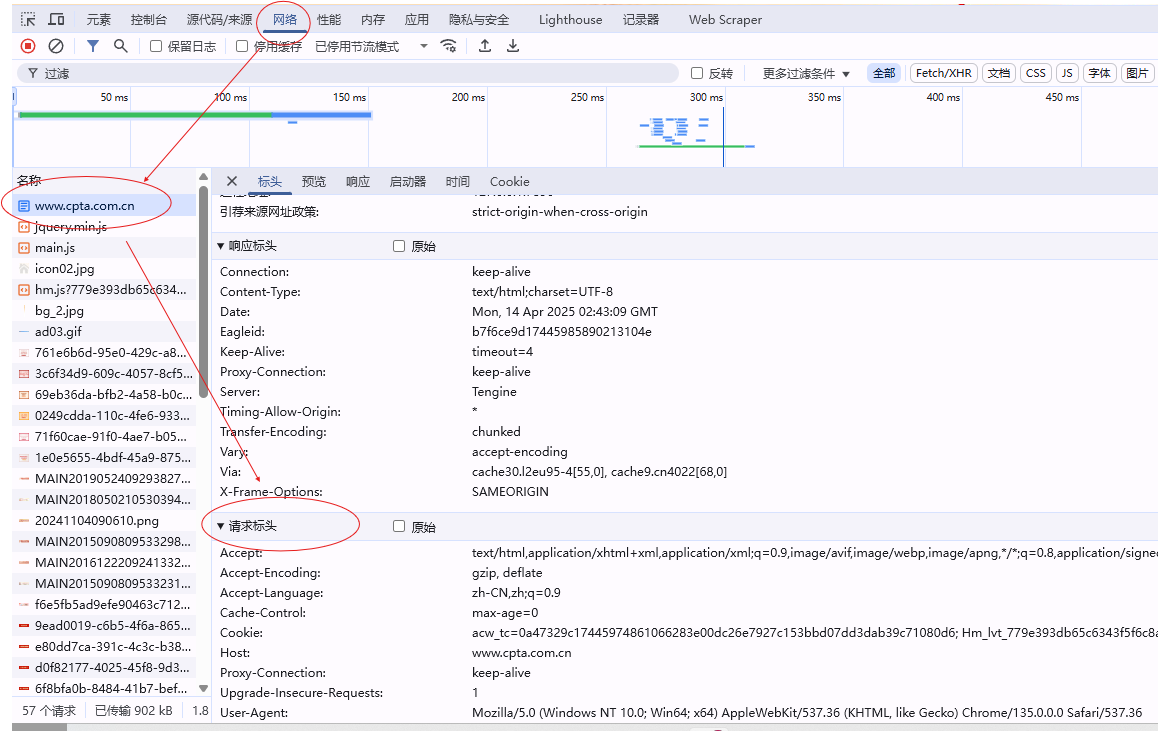
请求标头的就是正常用户提出请求会携带的数据,而先前的代码中并没有这些,所谓的反爬机制就是这样找到你模拟不够完善的地方,然后组织爬虫代码访问,但并不是说请求头中的所有都需要填进去,多数仅需要UA和cookie就可以使得代码正常运行(对应数据按照上述图去找到复制即可)
1 | import requests |
当然获取的文件中可能会只包含数据,一些网站的设计排版不一定会有,但数据爬到就可以了
如果我们想要更进一步搜索,比如想搜“人力资源”相关的信息,肯定还需要另外的代码,在写之前可以去实际网页搜索试试,看看网址有什么关系
你会发现这个页面和之前的51游戏页面有有所不同这里的网址值只有search,无论你搜什么关键词,网址都只是这个,此时你可以打开F12,查看相关信息,你会发现与之前的请求方式不同,这个页面采用的是post请求方式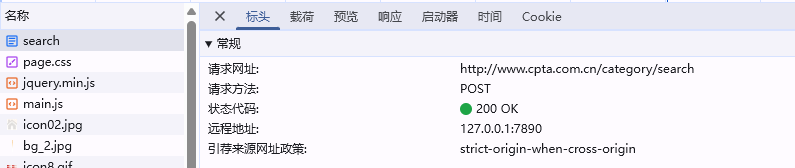
post数据往往会返回数据存储在json文件中,所以你应当去找对应的数据,也就是标头右边的载荷
将这里的数据复制到代码中再进行爬虫就可以达成效果
1 | import requests |
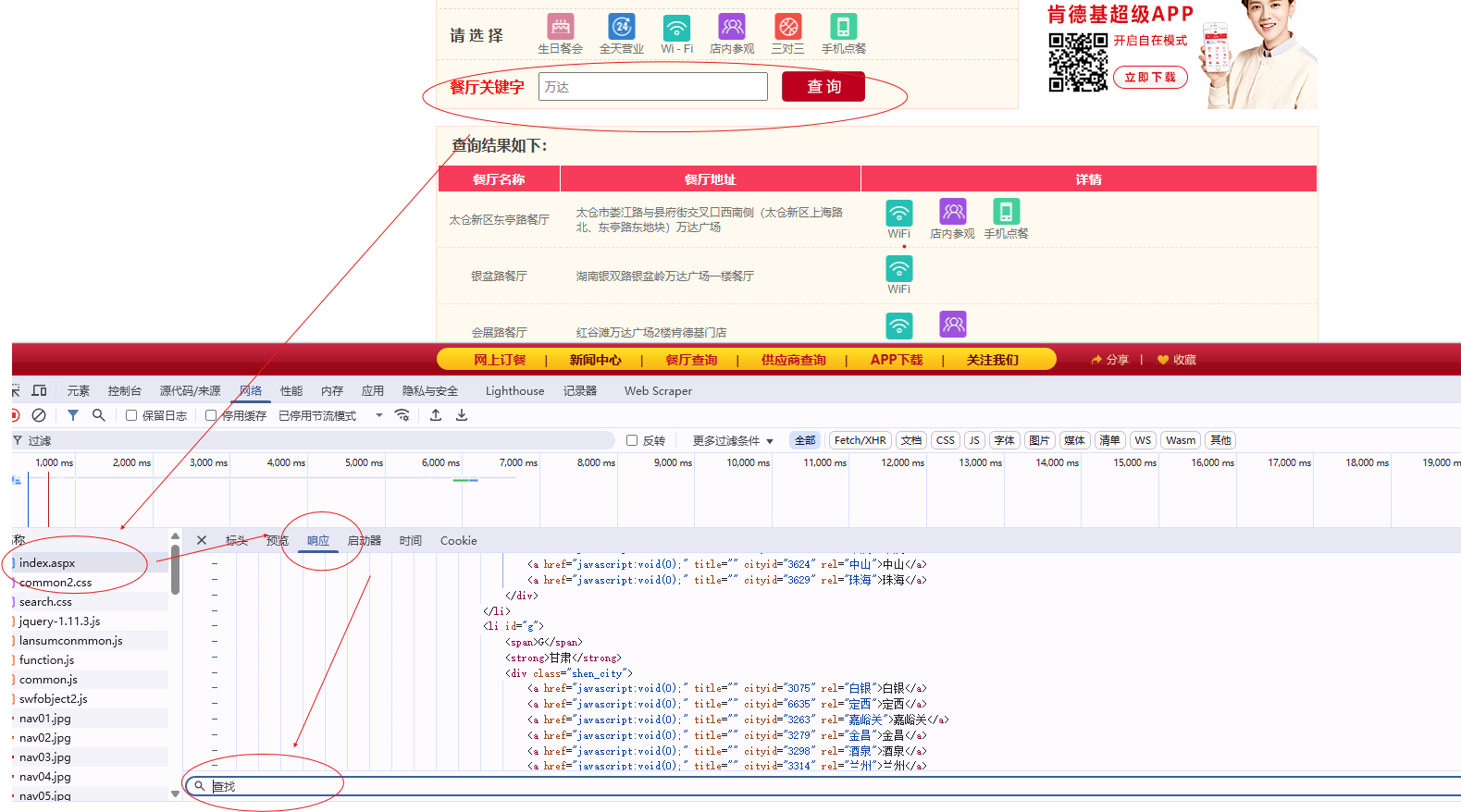
4. KFC餐厅
- 网址:http://www.kfc.com.cn/kfccda/storelist/index.aspx
在这里你若是想要通过关键词去进行查询你会发现,它并不会挑跳转到新网址,但是你若是按原本网址来却只能获取到无搜索时的数据。
这是因为在页面数据中有一种数据名为动态数据,动态加载数据值不是直接通过浏览器地址栏的url请求到的数据,这些数据叫做动态加载数据。
那么怎么判别数据是否是动态数据呢?你可以通过开发者模式,进入到当前页面的network
查找窗口可以通过ctrl+f 进行呼出,输入关键词,然后在响应中去搜索关键词看看是否能找到对应的数据,若无贼说明是动态数据
可以通过动态数据左上角的全局搜索进行找到对应文件
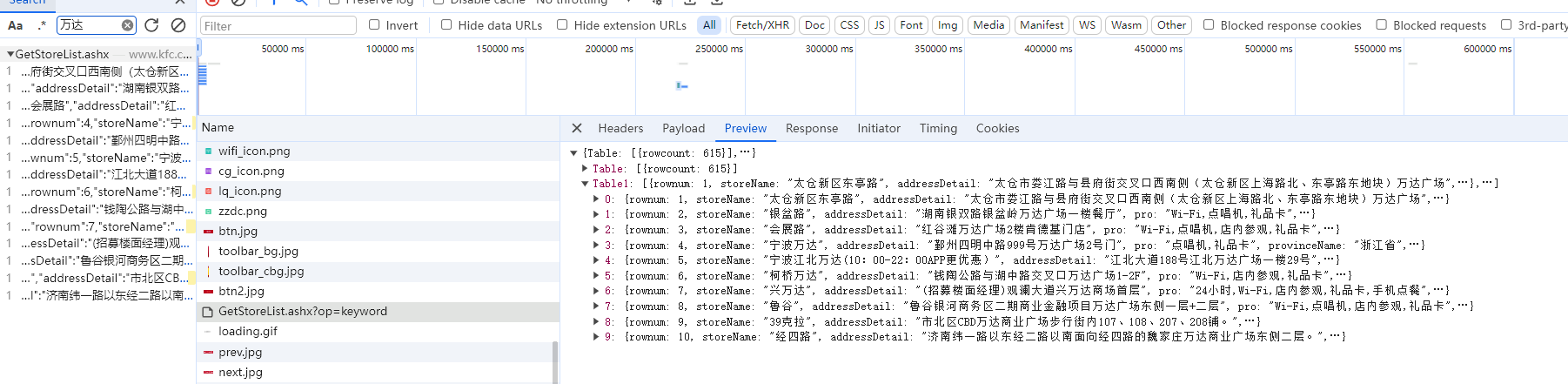
动态数据往往会用json存储,所以写代码的时候得留意,并且数据往往不止一页,有多页,需要采取多页连续采取1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import requests
key_word = input('请输入关键词:')
page_input = input('请输入页码(如1-5或1,2,3):')
pages=[]
if '-' in page_input:
start,end = map(int, page_input.split('-'))
pages= list(range(start, end+1))
else:
pages = [int(page_input)]
with open('kfc1.txt','w',encoding='utf-8') as f:
f.write("门店名称\t地址\n") # 写入表头
for page in pages:
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}
data = {
'cname':'' ,
'pid': '',
'keyword': key_word,
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url=url,headers=header,data=data)
response.encoding= 'utf-8'
page_KFC = response.json()
for detail in page_KFC['Table1']:
storename = detail.get('storeName', 'N/A')
add = detail.get('addressDetail', 'N/A')
f.write(f"{storename}\t{add}\n")
print(f"成功保存:{storename}-{add}")